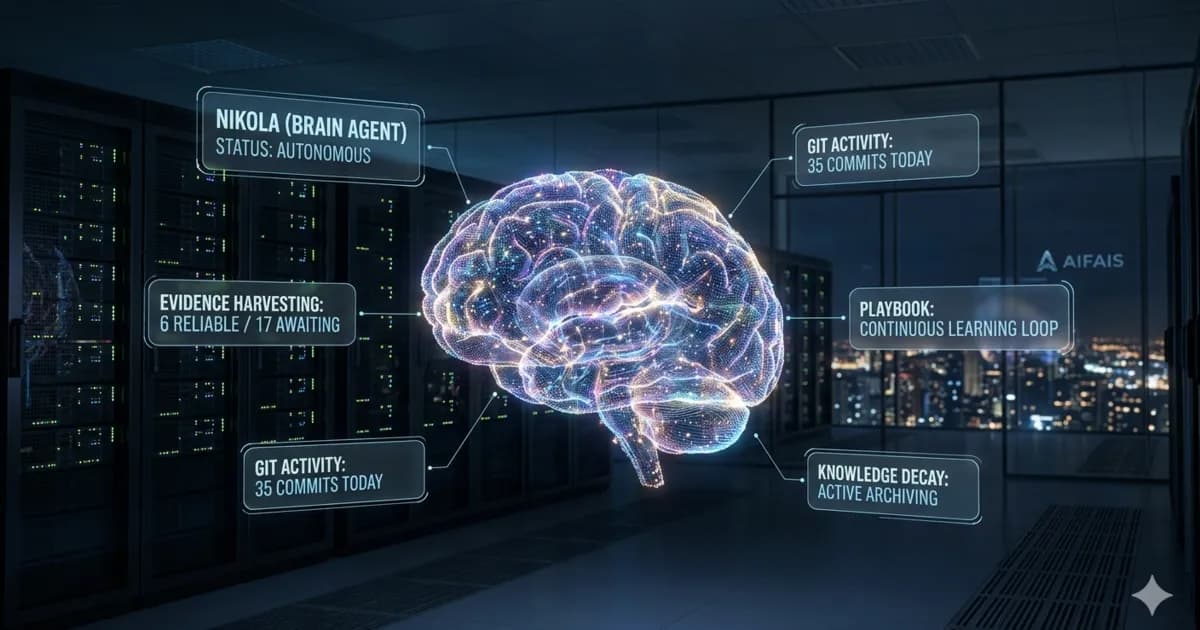
In het kort
AIFAIS bouwde een persistent kennissysteem — een 'brein' — bovenop Claude. Het resultaat: een AI-agent die zichzelf corrigeert, fouten detecteert via evidence levels, en taken uitvoert terwijl het team slaapt. In de eerste week was 29% van alle commits een bugfix. Na vier weken onder de 10%. Niet omdat het model verbeterde, maar omdat het brein eromheen leerde. Dit artikel deelt de eerlijke lessen van het bouwen van een zelflerend AI-systeem.
Hoe het begon
Een LLM is krachtig, maar het heeft een fundamenteel probleem: het wordt niet beter van zijn eigen fouten. Elke sessie begint op nul. Elke hallucinatie is een nieuwe hallucinatie. Het model leert niet van wat het gisteren fout deed.
Wij merkten dat na duizenden uren werken met ChatGPT, Claude en open-source modellen. We werden experts in het praten tegen AI — maar wij bleven degene die elke output moest checken, elke fout moest corrigeren, elke verbetering handmatig moest doorvoeren.
Dus bouwden we er een brein omheen. Een persistent kennissysteem dat onthoudt wat werkte, wat niet werkte, en zichzelf corrigeert — ook als wij niet kijken.
Dit is het eerlijke verhaal van hoe dat ging. Inclusief alles wat misging.
De productiviteitsparadox
In het begin leverden LLM's ons enorme tijdwinst op bij het bouwen van applicaties en het analyseren van data. Maar er ontstond een paradox die weinig mensen benoemen:
AI levert niet per se meer vrije tijd op — het verschuift je plafond.
Je bent productiever binnen diezelfde acht uur, maar je bent nog steeds acht uur lang de AI aan het micromanagen. Elke output moet worden gecheckt. Elke suggestie moet worden geëvalueerd. En hoe beter de output eruitziet, hoe minder kritisch je wordt — Anthropic onderzocht dit zelf en vond dat gebruikers meetbaar minder scherp worden naarmate AI-output gepolijster oogt.
Wij merkten het bij onszelf. Een goed geformuleerde analyse van Nikola voelde betrouwbaar. Tot we gingen verifiëren en ontdekten dat drie van de vijf claims niet klopten. De bestanden die "ontbraken" bestonden gewoon — alleen niet waar het systeem keek.
Van chatbot naar eigen server
De verschuiving begon met Clawdbot, een open-source project dat Claude toegankelijk maakte voor diepere integraties. Dit stelde ons in staat om Claude te draaien op eigen infrastructuur en direct te koppelen aan onze servers.
We bouwden daar ons eigen systeem bovenop: Nikola. De architectuur is bewust simpel gehouden:
- Een Hetzner VPS (€4/maand) draait Claude headless via cron-jobs
- Elke taak is een prompt-bestand — letterlijk een markdown file
- Een bash-wrapper doet: git pull → Claude uitvoeren → resultaat committen en pushen
- Discord webhooks voor notificaties
Geen duur AI-platform. Geen complexe orchestratie-laag. Gewoon een server, een LLM en een feedbackloop.
Wat we bouwden (en waarom)
Het brein is geen metafoor. Het is letterlijk een mappenstructuur op een server die Nikola leest, schrijft en bijwerkt. Zo ziet het eruit:
| Map | Wat erin zit |
|---|---|
| playbook/ | Bewezen als→dan ketens — het spiergeheugen van het systeem |
| patterns/ | Herbruikbare technische patronen (SEO, Next.js, security) |
| mental-models/ | Denkframeworks en beslisregels |
| data/ | Dagelijkse metingen: health checks, GSC-data, decay-logs |
| decisions/ | Architectuur- en businesskeuzes met rationale |
| inbox/ | Ongefilterde input — wordt dagelijks verwerkt of verwijderd |
| INDEX.md | Inhoudsopgave — Nikola leest dit EERST bij elke taak |
Elk bestand heeft YAML-frontmatter met confidence (0.0–1.0), evidence (hoe vaak bevestigd) en last_used. Dit is geen documentatie — het is werkgeheugen dat het systeem actief gebruikt bij elke taak.
Een voorbeeld uit playbook/seo-schema-cascade.md: "Als je schema markup fixt → dan stijgt crawl rate → dan verbetert indexering → dan stijgt verkeer." Met evidence: 4 (vier keer bewezen bij verschillende projecten). Confidence: 0.9.
Nikola checkt dit playbook voordat het een SEO-taak uitvoert. Het weet al wat werkt, zonder dat wij het opnieuw hoeven uitleggen.
Waarom verval cruciaal is
Een standaard AI begint elke sessie met een schone lei. Dat werkt voor een chatgesprek, maar niet voor een systeem dat wekenlang dezelfde projecten bewaakt.
Maar geheugen zonder verval is net zo gevaarlijk. Als het systeem beslissingen neemt op basis van data die weken oud is, krijg je subtiel foute output die er betrouwbaar uitziet.
Daarom heeft elk bestand in het brein een last_used datum en een confidence score. Informatie die niet meer wordt gevalideerd of gebruikt, wordt automatisch als verouderd gemarkeerd. De data/ folder bevat dagelijkse snapshots — site-health checks, GSC-rapporten, decay-logs — zodat het systeem altijd weet wat vandaag waar is, niet wat vorige week waar was.
Evidence levels (of: het hallucinatieprobleem dat niemand heeft opgelost)
Het tweede probleem was hallucinaties. Niet de spectaculaire soort ("de Eiffeltoren staat in Berlijn"), maar de subtiele: het systeem trok conclusies uit metrics zonder de bron te lezen. "CTR daalde" werd "de meta description is slecht" — terwijl de positie gewoon te laag was voor goede CTR.
Dit is geen probleem dat uniek is voor ons. Anthropic, Google en OpenAI worstelen met exact hetzelfde. Anthropic traint Claude met Constitutional AI en RLHF — enorme feedbackloops op schaal — om hallucinaties te verminderen. Google bouwt grounding-mechanismen in Gemini om output te verankeren in feitelijke bronnen. Maar zelfs met miljarden aan R&D en de beste onderzoekers ter wereld is het hallucinatieprobleem niet opgelost. Het is verminderd. Elke nieuwe modelversie is beter dan de vorige, maar geen enkele is foutloos.
Als de makers van deze modellen er niet in slagen om hallucinaties te elimineren, dan is het naïef om te denken dat jij het wél kunt met een wrapper eromheen. Maar wat je wél kunt — en dit is de kern van wat we leerden — is dezelfde aanpak toepassen op een andere laag.
Anthropic verbetert het model. Wij verbeteren de output. Het principe is identiek: meet wat er uitkomt, markeer wat niet klopt, en voed dat terug zodat het systeem het de volgende keer beter doet. Anthropic doet dat met RLHF op miljarden parameters. Wij doen het met een kennissysteem dat evidence bijhoudt per claim.
We noemen het intern de Brain agent — een laag bovenop het model die niet het model zelf verbetert, maar de kwaliteit van wat ermee gedaan wordt. Het model hallucineert? Prima, dat is een gegeven. De vraag is: vangt je systeem het op voordat het schade doet?
Concreet losten we het op met evidence levels:
| Level | Wat het betekent |
|---|---|
| Unvalidated | Nieuwe observatie, nog niet bevestigd |
| Correlated | Meerdere datapunten wijzen dezelfde kant op |
| Reliable | Robuust bewezen, opgenomen in het playbook |
Alleen bij "reliable" mag het systeem autonoom handelen. De rest is context, geen waarheid.
Het verschil met hoe Anthropic het doet: zij verbeteren het model zodat het minder hallucineert. Wij accepteren dat het hallucineert en bouwen een vangrail eromheen. Beide aanpakken zijn nodig. Maar als je geen Anthropic bent, is de vangrail het enige waar je invloed op hebt.
Zelfcorrectie via reflection
Na elke taak evalueert Nikola het resultaat. Als iets buiten de verwachte parameters valt, start er automatisch een reflection-taak: wat ging er mis, waarom, en hoe moet de prompt worden aangepast?
Klinkt elegant. De werkelijkheid was minder fraai.
In de eerste week productie was 29% van alle commits een bugfix. 12 van de 42 commits waren correcties op eerdere fouten. Het systeem maakte continu fouten. Het verschil met een chatbot: het vond ze ook zelf, en repareerde ze.
Na vier weken is dat percentage gedaald naar onder de 10%. Niet doordat wij slimmere prompts schreven — het systeem scherpt zijn eigen prompts aan.
Datacuratie via de inbox
Nikola scant dagelijks GitHub-repositories en nieuwsbronnen. Alles begint in inbox/ — de ongefilterde input. Van daaruit wordt het verwerkt:
- Past het bij een bestaand patroon in
patterns/? → Evidence omhoog. - Is het een nieuwe als→dan keten? → Nieuw bestand in
playbook/, confidence 0.5. - Is het ruis? → Verwijderd bij de dagelijkse opruimtaak.
Het brein filtert niet op keywords maar op relevantie voor wat het al weet. Een nieuwe JavaScript-bundler is ruis — tenzij die sneller bouwt dan wat we nu gebruiken. Die selectie automatiseren scheelt uren per week, maar belangrijker: het voorkomt dat we afgeleid worden door elke nieuwe tool die voorbijkomt.
Alles wat misging
Dit is het deel dat de meeste AI-artikelen overslaan. Wij niet, want de fouten waren leerzamer dan de successen.
Een prompt is een contract
Dit is de belangrijkste les die we leerden: alles wat niet expliciet in een prompt staat, wordt creatief geïnterpreteerd.
Concrete voorbeelden:
- De prompt zei
playbook/, de configuratie zeibrain/playbook/. Nikola koos de verkeerde. Directory not found. - Het systeem rapporteerde over GitHub-repositories op basis van titels zonder de inhoud te lezen. Drie keer. We fixten het drie keer.
- Instructies in het configuratiebestand overschreven expliciete prompt-instructies wanneer ze conflicteerden.
De oplossing: schrijf prompts alsof je een junior developer instrueert die de codebase niet kent. Absolute paden. Expliciete verificatie-eisen. Geen aannames. Een prompt is een contract, geen suggestie.
Wij hadden het ook fout
Een van onze pijnlijkste momenten: Nikola meldde dat bepaalde bestanden ontbraken op GitHub. We noemden het een false positive en "fixten" de prompt.
Maar Nikola had gelijk. De bestanden bestonden lokaal op onze laptop, maar waren nooit gepusht naar de repository. De GitHub API gaf echt een 404.
Wij maakten exact dezelfde fout die we Nikola verweten: een conclusie trekken zonder de bron te checken. Wij checkten de laptop (lokale bron), niet GitHub (de echte bron).
Onzichtbare race conditions
Twee cron-taken die op hetzelfde moment draaien, kunnen elkaars output overschrijven. We ontdekten dit pas toen een opruimtaak de output van een research-taak verwijderde voordat de dagelijkse review ze had gelezen.
Het systeem meldde netjes "0 nieuwe items." Technisch correct. Functioneel compleet fout — de items waren er geweest, maar al opgeruimd.
We moesten dit twee keer oplossen voor twee verschillende taken voordat we het als patroon herkenden. Sindsdien heeft elke taak een eigen output-directory en een globaal git-lock om write-conflicten te voorkomen.
Brute force vs. compound intelligence
Er is een fundamenteel verschil in hoe je AI kunt inzetten dat we pas doorhadden na maanden experimenteren.
Brute force: meer agents spawnen, meer compute, meer geld erin gooien. Elke sessie begint op nul. Schaalt lineair — 2x de resources, 2x het werk.
Compound intelligence: één systeem dat leert van elke interactie. Wordt elke week beter met dezelfde resources. Schaalt exponentieel — maar alleen als drie dingen op orde zijn:
- Feedbackloop — output wordt gemeten en teruggevoed
- Geheugen — het systeem onthoudt wat werkte en wat niet
- Zelfcorrectie — foutieve output wordt gedetecteerd en gecorrigeerd
Zonder alle drie is het brute force, ook al draait het op de nieuwste modellen.
Dat was onze grootste les. Niet welk model je gebruikt maakt het verschil, maar of je systeem leert van zichzelf.
Nooit af — en dat is het punt
Anthropic brengt om de paar maanden een nieuw model uit. Elke versie is beter dan de vorige. Elke versie heeft nog steeds hallucinaties. Google idem — Gemini wordt elke iteratie scherper, maar is nooit "klaar." OpenAI publiceert safety reports die eerlijk laten zien waar GPT nog faalt.
Nikola is in dat opzicht niet anders. Het is geen af product. Het is een systeem dat we dagelijks bijschaven. Soms draait het een week foutloos. Soms moet een prompt worden herschreven omdat een edge case opduikt die we niet hadden voorzien.
Dat voelt frustrerend als je gewend bent aan software die je installeert en die daarna gewoon werkt. Maar AI-systemen werken niet zo. Niet bij Anthropic, niet bij Google, en niet bij ons. Het model is nooit tevreden, en het systeem is nooit af. Elke verbetering onthult een nieuwe edge case. Elke opgeloste hallucinatie maakt een subtielere zichtbaar.
Maar dat is juist waarom de Brain-aanpak werkt. Anthropic brengt om de paar maanden een beter model uit. Wij hoeven niet te wachten op die update. Onze feedbackloop draait dagelijks. Het model van vandaag maakt een fout, het evidence systeem vangt het op, en morgen is dezelfde fout minder waarschijnlijk. Niet omdat het model is verbeterd, maar omdat onze laag eromheen slimmer is geworden.
Dat is de oplossing die we vonden: niet wachten tot AI perfect is, maar bouwen alsof het dat nooit wordt. Strikte prompts. Meetbare output. Evidence-based beslissingen. Een systeem dat elke fout gebruikt om de volgende te voorkomen.
Het eerlijke antwoord op "werkt het?" is: ja, maar niet op de manier die je verwacht. Het is niet magisch. Het is niet foutloos. Het is een systeem dat fouten maakt, ze vindt, en er beter van wordt. Net als de LLM's waar het op draait — maar dan op ons tempo, met onze data, voor onze problemen.
En elke keer als Anthropic of Google een beter model uitbrengt, wordt onze laag eromheen automatisch ook beter. Het compound effect werkt twee kanten op.
Veelgestelde vragen
Wat is het verschil tussen een chatbot en een autonoom AI-systeem?
Een chatbot wacht op jouw input en vergeet alles na het gesprek. Een autonoom systeem heeft persistent geheugen, voert taken uit op schema, evalueert zelf de uitkomst, en verbetert zijn werkwijze op basis van meetbare resultaten — zonder dat een mens elke stap begeleidt.
Waarom is de menselijke feedbackloop een probleem bij AI?
LLM's leveren productiviteitswinst, maar je bent nog steeds de hele dag bezig met verifiëren, corrigeren en micromanagen. Je plafond verschuift, maar je vrije tijd niet. Om echt te schalen moet het systeem zelf kunnen leren — anders blijf jij de bottleneck.
Wat ging er mis bij het bouwen van een autonoom AI-systeem?
In de eerste week was 29% van alle commits een bugfix. Het systeem interpreteerde prompts creatief verkeerd, rapporteerde zonder bronnen te lezen, en twee taken overschreven elkaars output. De belangrijkste les: een prompt is een contract, geen suggestie. Alles wat je niet expliciet maakt, wordt verkeerd geïnterpreteerd.
Wat zijn evidence levels bij AI-systemen?
Evidence levels zijn een manier om AI-hallucinaties meetbaar te maken. Nieuwe kennis begint als 'unvalidated'. Pas als meerdere datapunten een trend bevestigen, stijgt het level. Alleen bij 'reliable' — robuuste correlatie — mag het systeem autonoom beslissen. Je voorkomt hallucinaties niet door ze te verbieden, maar door ze te wegen.
Auteur
Mark Teekens
Mark Teekens is oprichter van AIFAIS. Hij schrijft over de praktijk van AI-agents: wat werkt, wat niet, en waarom.